- Faculty Name
- Jae-Woo Chang
- Reserach Area
- Data mining methods on the encrypted databases ․ Distributed parallel classification algorithm on the encrypted data
- Phone
- 063) 270-2414
- Website
- ttp://dblab.jbnu.ac.kr
- Location
- 공대 7호관 401호
Reserach Interest
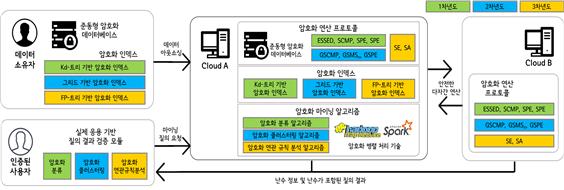
The existing data mining methods on the encrypted database has a problem in that the access pattern is exposed to the cloud server, and high processing cost is required because all data are considered for data mining. In order to solve this problem, we study efficient data mining methods on encrypted databases. For this works, first, we study a privacy-preserving classification method that provides both security and efficiency on encrypted databases. Second, we study a privacy-preserving clustering method that provides security and efficiency on the encrypted database. Finally, we study a the privacy-preserving association rule mining method that provides both security and efficiency on the encrypted database. Figure 1 shows the data mining methods on the encrypted database.
2. The research of distributed parallel classification algorithm
We propose a distributed parallel classification algorithm based on Hadoop Map-Reduce by extending the previously proposed classification algorithm. In the proposed algorithm, we distribute the encrypted data to each server based on the node ID of kd-trees for parallel processing. The overall process consists of four steps as shown in figure 2: i)searching the encrypted index, ii)searching the kNN for classification, iii)verifying the query results, iv)classifying the categories.
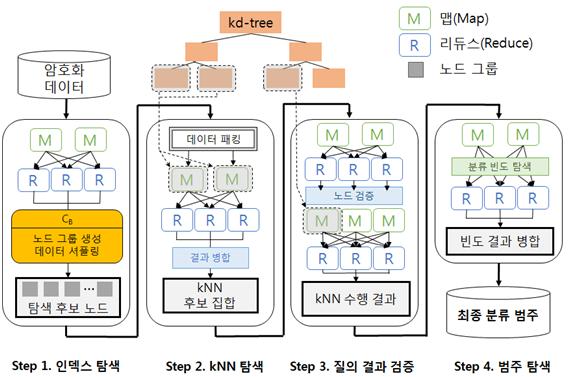
i) In the encrypted index search step, we use the map function to allocate encrypted nodes to multiple distributed servers evenly, and use the reduce function to search for node candidates in the kd-tree adjacent to the query for the allocated nodes(Step 1).
ii) In the kNN search step for classification, each server independently searches for kNN candidates using a plurality of reduce functions, and merges the results to generate a final set of kNN data candidates(Step 2). iii) The verifying step allocates a set of kNN data candidates to each distributed server for each node by using a map function, and searches for nodes closer to the kNN query candidates found in the previous step by using a reduce function. If a nearby node is found, the final kNN is searched again through additional MapReduce (Step 3). iv) In the classification step, the classification category of kNN data candidates is searched using a map function, and the category frequency of kNN data is calculated using a reduce function to determine the final classification category to which the query belongs.
Introduction
Lab Features : Database Lab features are as follows.
-First, you can conduct in-depth research on the latest fields of database such as information protection and cloud computing.
-Second, working skills improvement and research fund support are possible by participating in various related projects.
-Third, it is possible to acquire major knowledge and cultivate communication skills through senior junior relationship with family atmosphere.